隣の席でスクレイピングした結果をスプレッドシートにコピペする業務をしているので、だったら Google Apps Script でスクレイピングして直接スプレッドシートに書き出せばいいんじゃない?ってことでやり方を調べてみた。
HTML ソースを取得する
Chronium とか、難しことは考えずにとりあえず、生の HTML を取得する。
1
2
3
4
5
6
7
| function myFunction() {
const getUrl = "https://al-batross.net/";
const html = UrlFetchApp.fetch(getUrl).getContentText('UTF-8');
Logger.log(html);
}
|
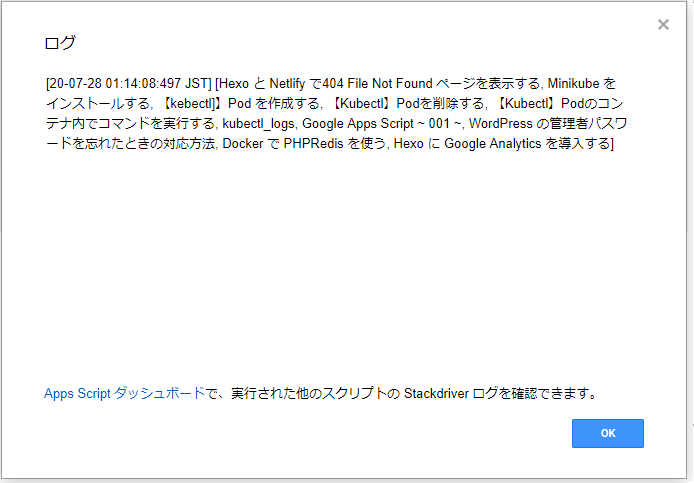
ログを確認すると長すぎるので途中までしか表示しないよ、と言われるが HTML の取得には成功しているっぽい。
必要な部分を切り出す
HTML の全体を取得しても扱いに困るので、必要な部分だけが欲しい。Parser を使って切り出してみる。
Parser ライブラリを導入する
Parser を自分で組むのは面倒なので、ライブラリを導入したい。
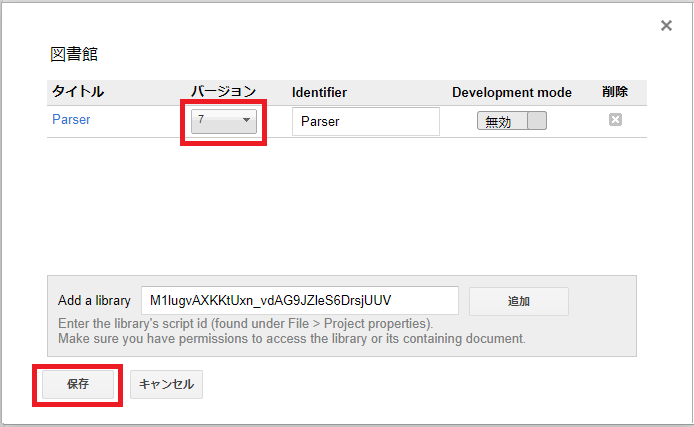
[リソース]をクリックする
[ライブラリー]をクリックする
[Add a library]にライブラリーの識別子 M1lugvAXKKtUxn_vdAG9JZleS6DrsjUUV を入力し、[追加]ボタンをクリックす
る
[バージョン]で最新の 7 を選択し、[保存]ボタンをクリックする
ブログのタイトルを取得する
先程のコードに Parser を追加してみた。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| function myFunction() {
const getUrl = "https://al-batross.net/";
const fromText = '<title>';
const toText = '</title>';
const content = UrlFetchApp.fetch(getUrl).getContentText('UTF-8');
const scraped = Parser
.data(content)
.from(fromText)
.to(toText)
.build();
Logger.log(scraped);
}
|
どうやら、この Paser は切り出す部分を DOM で指定するのではなく、fromText と toText の間の文字列を切り取って、と指定するらしい。
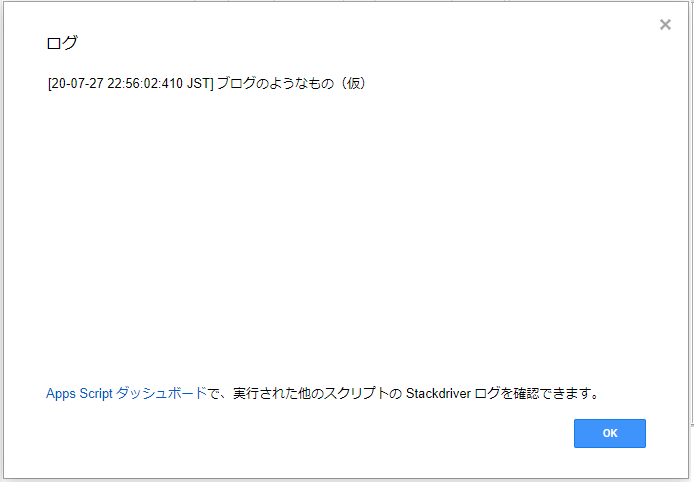
実行結果はこんな感じ。ちゃんと取れてる。
ブログのタイトルは1つだけ取得すればいいので、build() を使ったが、複数ある記事の URL のリストを取得するには、iterate()を使う。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| function myFunction() {
const getUrl = "https://al-batross.net/";
const fromText = '<a class="article-title" href="';
const toText = '">';
const content = UrlFetchApp.fetch(getUrl).getContentText('UTF-8');
const scraped = Parser
.data(content)
.from(fromText)
.to(toText)
.iterate();
Logger.log(scraped);
}
|
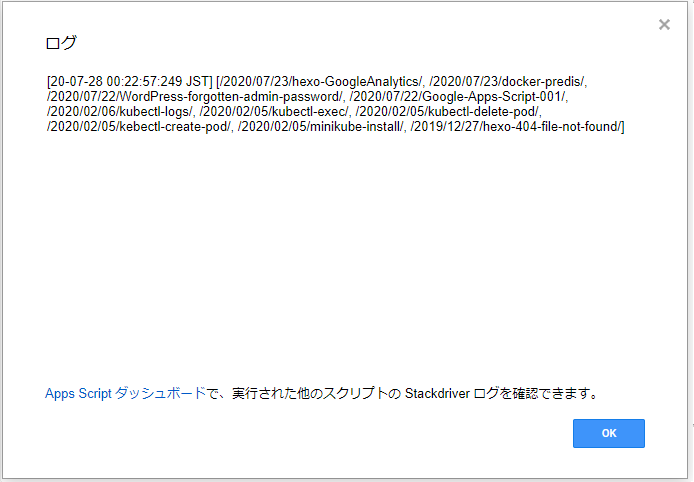
実行結果はこんな感じ。こちらも、ちゃんと取れてる。
Parser の問題点
便利なライブラリの Parser だが範囲指定で取得するので、細かい調整が難しい。
例えば、上記の例だと記事の URL のリストを取得したが、記事タイトルを取得しようとすると、<a class="article-title" href=".*">記事タイトル</a> と href が一意でないので指定できない。
ワイルドカードや正規表現でしていすることもできないようなので、あがいてみた結果、こうなった。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| function myFunction() {
const getUrl = "https://al-batross.net/";
const fromText = '<header class="article-header">';
const toText = '</header>';
const content = UrlFetchApp.fetch(getUrl).getContentText('UTF-8');
const articleList = Parser
.data(content)
.from(fromText)
.to(toText)
.iterate();
let articleTitleList = [];
for(var i = articleList.length-1; i >= 0; i--){
const regex = /<a class="article-title" href="[^"]*">(.*?)<\/a>/g;
if ((articleTitle = regex.exec(articleList[i]))!== null) {
articleTitleList.push(articleTitle[1])
}
}
Logger.log(articleTitleList);
}
|
ざっくりとした範囲指定で取得した articleList に対して、正規表現で取得したい記事タイトル部分を指定して切り出したものを記事タイトル配列 articleTitleList にぶち込んでみた。